Describing Data 👨💻
MATH 4720/MSSC 5720 Introduction to Statistics
Descriptive Statistics (Data Summary)
- Before doing inferential statistics, let’s first learn to understand our data by describing or summarizing it using a table, graph, or some important measures, so that appropriate methods can be performed for better inference results.
R Packages 📦
Packages wrap up reusable R functions, the documentation that describes how to use them, and data sets all together.
As of August 2025, there are about 22510 R packages available on CRAN (the Comprehensive R Archive Network)!
-
palmerpenguinspackage
![]()
Categorical Frequency Table palmerpenguins package ![]()
str(penguins)tibble [344 × 8] (S3: tbl_df/tbl/data.frame)
$ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ...
$ island : Factor w/ 3 levels "Biscoe","Dream",..: 3 3 3 3 3 3 3 3 3 3 ...
$ bill_length_mm : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
$ bill_depth_mm : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
$ flipper_length_mm: int [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
$ body_mass_g : int [1:344] 3750 3800 3250 NA 3450 3650 3625 4675 3475 4250 ...
$ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 NA NA ...
$ year : int [1:344] 2007 2007 2007 2007 2007 2007 2007 2007 2007 2007 ...x <- penguins[, "species"]Categorical Frequency Table: species
## frequency table
table(x)species
Adelie Chinstrap Gentoo
152 68 124 
Visualizing a Frequency Table: Bar Chart
Pie Chart
Body Mass (Grams) in Data penguins
body_mass <- penguins$body_mass_g
head(body_mass, 20) [1] 3750 3800 3250 NA 3450 3650 3625 4675 3475 4250 3300 3700 3200 3800 4400
[16] 3700 3450 4500 3325 4200body_mass <- body_mass[complete.cases(body_mass)]
Visualizing Frequency Distribution by a Histogram
Use default breaks (no need to specify)
hist(x = body_mass,
xlab = "Body Mass (gram)",
main = "Histogram (Defualt)")
Use customized breaks
class_boundary [1] 2700 3000 3300 3600 3900 4200 4500 4800 5100 5400 5700 6000 6300hist(x = body_mass,
breaks = class_boundary, #<<
xlab = "Body Mass (gram)",
main = "Histogram (Ours)")
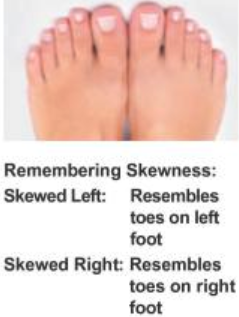
Skewness
Key characteristics of distributions includes shape, center and spread.
Skewness provides a way to summarize the shape of a distribution.
Remembering Skewness
Is the body mass histogram left skewed or right skewed?
Scatterplot for Two Numerical Variables
- A scatterplot provides a case-by-case view of data for two numerical variables.
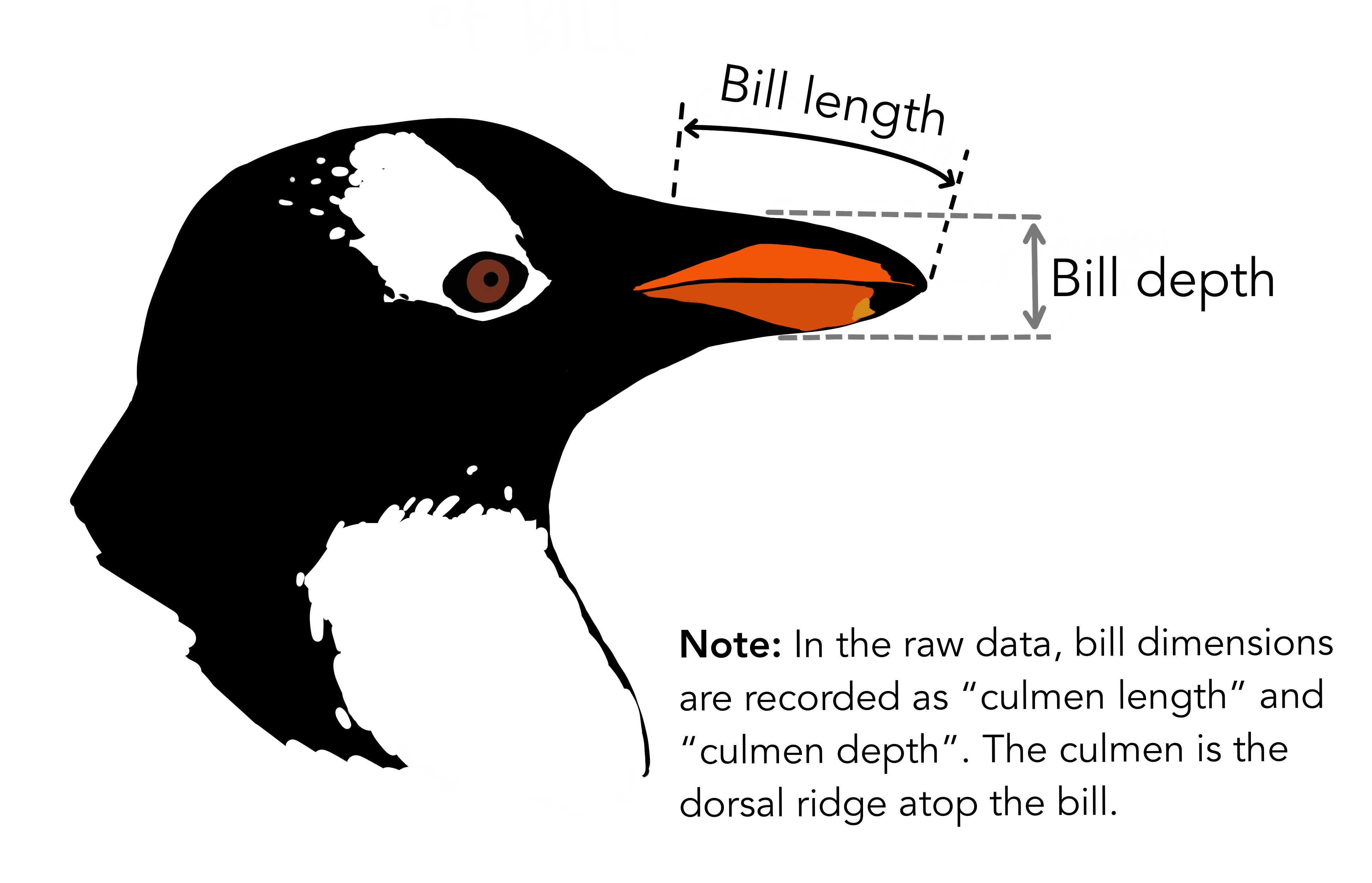
plot(x = penguins$bill_length_mm, y = penguins$bill_depth_mm,
xlab = "Bill Length", ylab = "Bill Depth",
pch = 16, col = 4)
Numerical Summaries of Data

If you need to choose one value that represents the entire data, what value would you choose?
Measure of Center: We typically use the middle point. (What does “middle” mean?)
Measure of Variation: What values tell us how much variation a variable has?
Balancing Point
- Think of the mean as the balancing point of the distribution.

Comparison of Mean, Median and Mode
Mode is applicable for both categorical and numerical data, while median and mean work for numerical data only.
There may be more than one mode, but there is only one median and one mean.
Measures of Variation
Measures of Variation: p-th percentile
-
p-th percentile (quantile): a data value such that
- at most \(p\%\) of the values are below it
- at most \((1-p)\%\) of the values are above it
- Two datasets with the same mean 20.
- One data set has 99-th percentile = 30, and 1-st percentile = 10.
- The other has 99-th percentile = 40, and 1-st percentile = 0.
- Which data have larger variation?
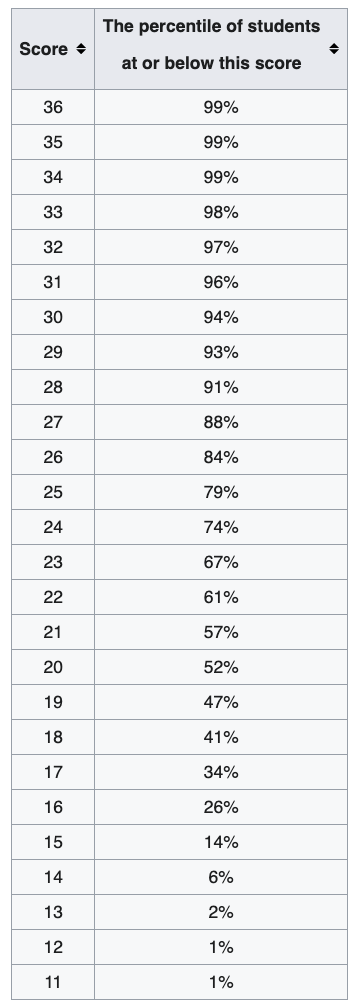
Visualizing Data Variation: Boxplot
When plotting the whiskers,
minimum value in the data means the minimal value that is not an potential outlier.
maximum value in the data means the maximal value that is not an potential outlier.
Body Mass Boxplot