
Sampling Distribution and Central Limit Theorem
MATH 4720/MSSC 5720 Introduction to Statistics
Parameter
-
Parameters in a probability distribution are the values describing the entire distribution.
- Binomial: two parameters \(n\) and \(\pi\)
- Poisson: one parameter \(\lambda\)
- Normal: two parameters \(\mu\) and \(\sigma\)
- In statistics, we usually assume our target population follows some distribution, but its parameters are unknown to us.
Human weight follows \(N(\mu, \sigma^2)\)
# of snowstorms in one year follows \(Poisson(\lambda)\)

Treat Each Data Point as a Random Variable
\(n\) random variables \(X_1, X_2, \dots, X_n\).
\(X_1, X_2, \dots, X_n\) come from the same distribution.
View \(X_i\) as a data point to be drawn from a population with some distribution, say \(N(\mu, \sigma^2)\).

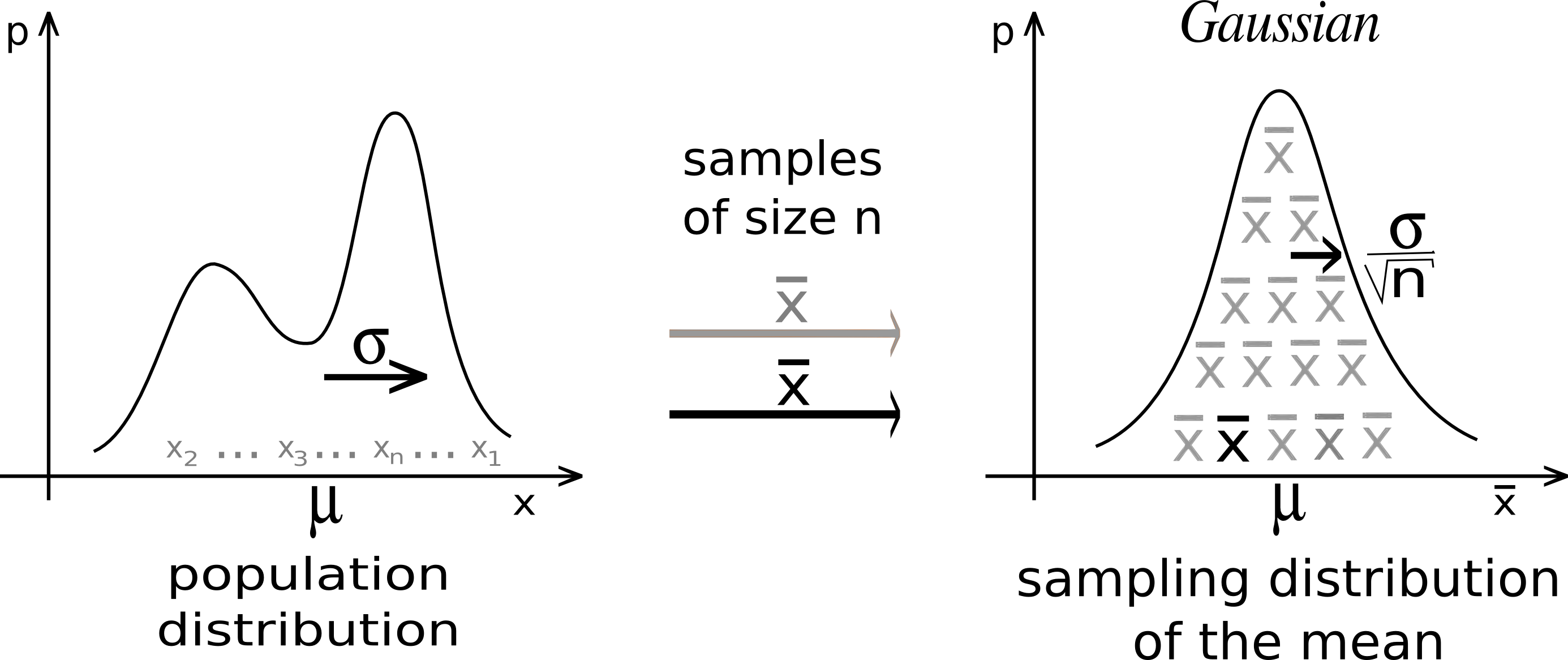
Sampling Distribution
- It is the probability distribution of that statistic if we were to repeatedly draw samples of the same size from the population.

Example: Sampling Distribution of the Sample Mean
Roll a fair die 3 times 🎲🎲 🎲 independently to obtain 3 values from the population \(\{1, 2, 3, 4, 5, 6\}\).
Repeat the process 10,000 times and plot the histogram of the sampling mean.


Sampling Distribution of Sample Mean Illustration

Example - Psychomotor retardation
Psychomotor retardation scores for a group of patients have a normal distribution with a mean of 930 and a standard deviation of 130.
What is the probability that the mean retardation score of a random sample of 20 patients was between 900 and 960?

- \(X_1, \dots, X_{20} \stackrel{iid}{\sim} N(930, 130^2)\), then \(\overline{X} = \frac{\sum_{i=1}^{20}X_i}{20} \sim N\left(930, \frac{130^2}{20} \right)\).
\[\small \begin{align} P(900 < \overline{X} < 960) &= P\left( \frac{900-930}{130/\sqrt{20}} < \frac{\overline{X}-930}{130/\sqrt{20}} < \frac{960-930}{130/\sqrt{20}}\right)=P(-1.03 < Z < 1.03)\\ &=P(Z < 1.03) - P(Z < -1.03) \end{align}\]
Why Use Normal? Central Limit Theorem
Central Limit Theorem (CLT):
Suppose \(\overline{X}\) is from a random sample of size \(n\) and from a population distribution having mean \(\mu\) and standard deviation \(\sigma < \infty\).
As \(n\) increases, the sampling distribution of \(\overline{X}\) looks more and more like \(N(\mu, \sigma^2/n)\), regardless of the distribution from which we are sampling!
CLT Illustration: A Right-Skewed Distribution

CLT Illustration: A U-shaped Distribution

CLT Example
Suppose that selling prices of houses in Milwaukee are known to have a mean of $382,000 and a standard deviation of $150,000.
In 100 randomly selected sales, what is the probability the average selling price is more than $400,000?

Since the sample size is fairly large \((n = 100)\), by CLT, the sampling distribution of the average selling price is approximately normal with mean 382,000 and SD \(150,000 / \sqrt{100}\).
\(P(\overline{X} > 400000) = P\left(\frac{\overline{X} - 382000}{150000/\sqrt{100}} > \frac{400000 - 382000}{150000/\sqrt{100}}\right) \approx P(Z > 1.2)\) where \(Z \sim N(0, 1)\).