
Analysis of Variance (ANOVA)
MATH 4720/MSSC 5720 Introduction to Statistics
Comparing More Than Two Population Means
In many research settings, we’d like to compare 3 or more population means.
4 types of devices used to determine the pH of soil samples.
Determine whether there are differences in the mean readings of those 4 devices.
- Do different treatments (None, Fertilizer, Irrigation, Fertilizer and Irrigation) affect the mean weights of poplar trees?

Rationale for ANOVA
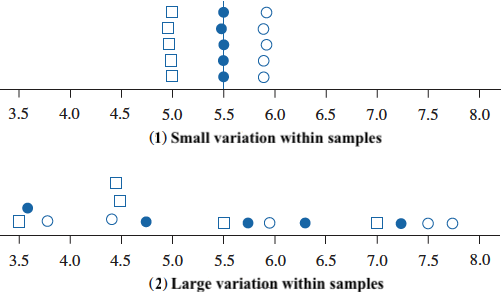
Data 1 and Data 2 have the same group sample means \(\bar{y}_1\), \(\bar{y}_2\) and \(\bar{y}_3\) denoted as red dots.
Which data you are more confident to say the population means \(\mu_1\), \(\mu_2\) and \(\mu_3\) are not all the same?
Variation Between Samples & Variation Within Samples
Data 1: Variability between samples is large in comparison to the variation within samples.
Data 2: Variation between samples is small relatively to the variation within samples.
More confident to conclude there is a difference in population means when variation between samples is relatively larger than variation within samples.
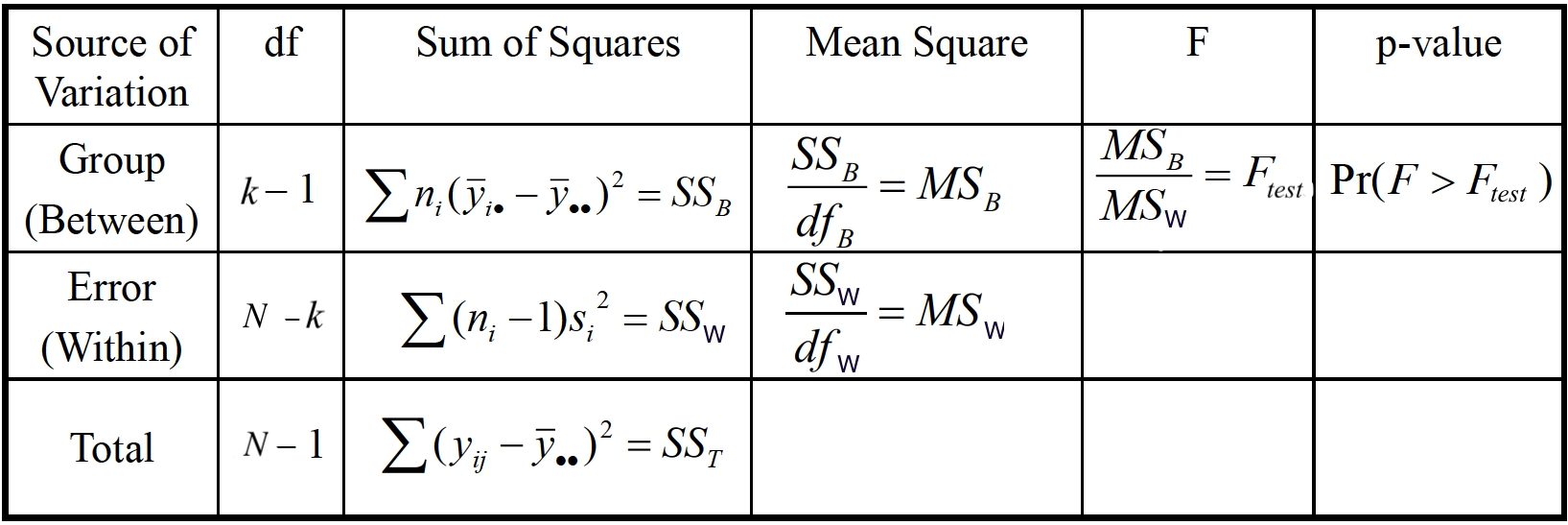
ANOVA Table
\(s_B^2\) and \(s_W^2\) as Sum of Squares/Degrees of Freedom
Variance is defined as \(\frac{\text{Sum of Squares}}{\text{Degrees of Freedom}}\), which is also called \(\text{Mean Square (MS)}\)
\(s_B^2 = \frac{\sum_{i=1}^k n_i (\bar{y}_{i} - \bar{y}_{})^2}{k-1} = \frac{\text{Sum of Squares Between Samples (SSB)}}{df_B} = MSB\)
\(s_W^2 = \frac{\sum_{i=1}^{k} (n_i - 1)s_i^2}{n_1 + n_2 + \cdots + n_k - k} = \frac{\text{Sum of Squares Within Samples (SSW)}}{df_W} = MSW\) \((N = n_1 + \cdots + n_k)\)
Sum of Squares Identity
\[\text{Total Sum of Squares (SST)} = \sum_{j=1}^{n_i}\sum_{i=1}^{k} \left(y_{ij} - \bar{y}_{}\right)^2 = SSB + SSW\]
\[df_{T} = df_{B} + df_{W} \implies N - 1 = (k-1) + (N - k)\]
Sum of Squares Identity
\(F_{test} = \frac{MSB}{MSW}\)
Under \(H_0\), \(\frac{S^2_{B}}{S_W^2} \sim F_{k-1, \, N-k}\)
-
Reject \(H_0\) if
- \(F_{test} > F_{\alpha, \, k - 1,\, N-k}\)
- \(p\)-value \(P(F_{k - 1,\, N-k} > F_{test}) < \alpha\)
Example
- A hypothesis is that a nutrient “Isoflavones” varies among three types of food: (1) cereals and snacks, (2) energy bars, and (3) veggie burgers.



A sample of 5 each is taken and the amount of isoflavones is measured.
Is there a sufficient evidence to conclude that the mean isoflavone levels vary among these food items? \(\alpha = 0.05\).
Example - Boxplot
Example - Test Assumptions
- Assumptions:
- \(\sigma_1 = \sigma_2 = \sigma_3\) (I tested it)
- Data are generated from a normal distribution for each type of food.
Example - ANOVA Testing
- \(\begin{align}&H_0: \mu_1 = \mu_2 = \mu_3\\&H_1: \mu_is \text{ not all equal} \end{align}\)
😎 Do all calculations and generate an ANOVA table using just one line of code! 🤟 ✌️
Example - ANOVA Table
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
food 2 60.4 30.20 0.828 0.46
Residuals 12 437.6 36.47