Dr. Cheng-Han Yu Department of Mathematical and Statistical Sciences Marquette University
Regression
What is Regression
Regression models the relationship between one or more numerical/categorical response variables \((Y)\) and one or more numerical/categorical explanatory variables \((X)\).
A regression function\(f(X)\) describes how a response variable \(Y\), on average, changes as an explanatory variable \(X\) changes.
Examples:
college GPA \((Y)\) vs. ACT/SAT score \((X)\)
sales \((Y)\) vs. advertising expenditure \((X)\)
crime rate \((Y)\) vs. median income level \((X)\)
Unknown Regression Function
The true relationship between \(X\) and the mean of \(Y\), the regression function \(f(X)\), is unknown.
The collected data \((x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\) is all we know and have.
Goal: estimate\(f(X)\) from our data and use it to predict value of \(Y\) given any value of \(X\).
Simple Linear Regression
Start with simple linear regression:
Only one predictor \(X\) (known and constant) and one response variable \(Y\)
the regression function used for predicting \(Y\) is a linear function.
use a regression line in a X-Y plane to predict the value of \(Y\) for a given value of \(X = x\).
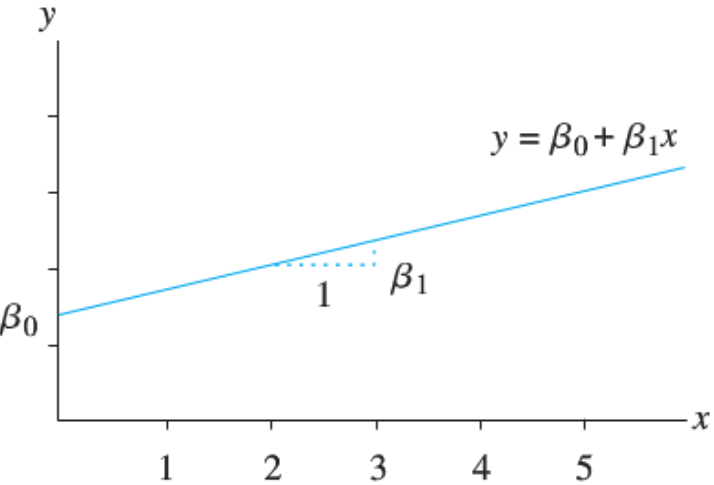
Math review: A linear function \(y = f(x) = \beta_0 + \beta_1 x\) represents a straight line
\(\beta_1\): slope, the amount by which \(y\) changes when \(x\) increases by one unit.
\(\beta_0\): intercept, the value of \(y\) when \(x = 0\).
The linearity assumption: \(\beta_1\) does not change as \(x\) changes.
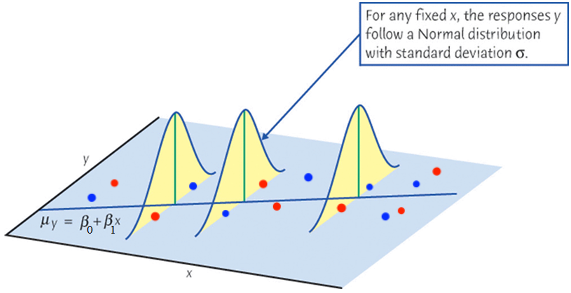
Sample Data: Relationship Between X and Y
Real data \((x_i, y_i), i = 1, 2, \dots, n\) do not form a perfect straight line!
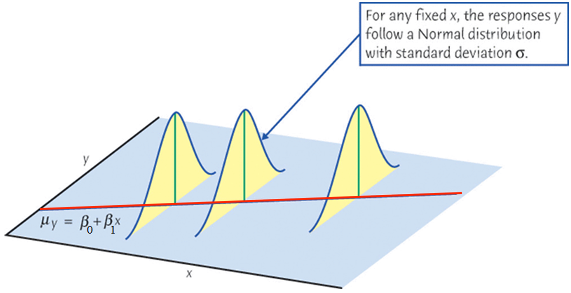
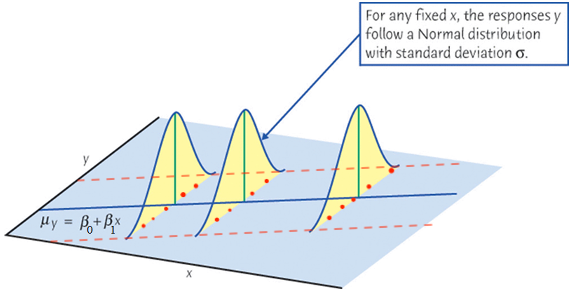
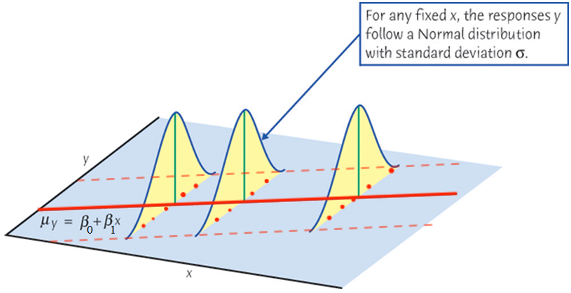
The mean response\(\mu_{Y\mid X}\) has a straight-line relationship with \(X\) given by a population regression line \[\mu_{Y\mid X} = \beta_0 + \beta_1X\]
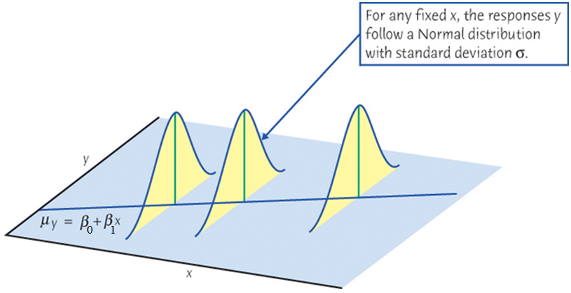
Important Features of Model \(Y_i = \beta_0 + \beta_1X_i + \epsilon_i\)
\(\epsilon_i \stackrel{iid}{\sim} N(0, \sigma^2)\)\[\begin{align*}
\mathrm{Var}(Y_i \mid X_i) &= \mathrm{Var}(\epsilon_i) = \sigma^2
\end{align*}\] The variance of \(Y\) does not depend on \(X\).
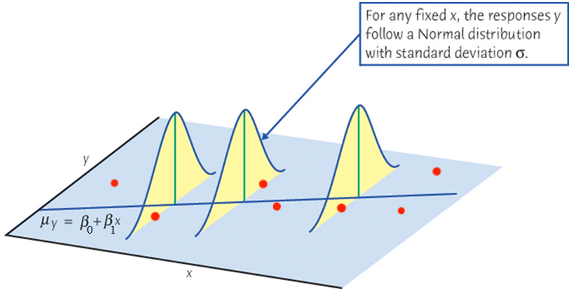
Important Features of Model \(Y_i = \beta_0 + \beta_1X_i + \epsilon_i\)
\(\epsilon_i \stackrel{iid}{\sim} N(0, \sigma^2)\)\[\begin{align*}
Y_i \mid X_i \stackrel{indep}{\sim} N(\beta_0 + \beta_1X_i, \sigma^2)
\end{align*}\] For any fixed value of \(X_i = x_i\), the response \(Y_i\) varies with \(N(\mu_{Y_i\mid x_i}, \sigma^2)\).
Job: Collect data and estimate the unknown parameters \(\beta_0\), \(\beta_1\) and \(\sigma^2\)!
Idea of Fitting
Interested in \(\beta_0\) and \(\beta_1\) in the following sample regression model: \[\begin{align*}
y_i = \beta_0 + \beta_1~x_{i} + \epsilon_i,
\end{align*}\]
Use sample statistics \(b_0\) and \(b_1\) computed from our sample data to estimate \(\beta_0\) and \(\beta_1\).
\(\hat{y}_{i} = b_0 + b_1~x_{i}\) is called fitted value of \(y_i\), a point estimate of the mean \(\mu_{y|x_i}\) and \(y_i\) itself.
Fitting a Regression Line \(\hat{Y} = b_0 + b_1X\)
Given the sample data \(\{ (x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\},\)
Which sample regression line is the best?
What are the best estimators \(b_0\) and \(b_1\) for \(\beta_0\) and \(\beta_1\)?
Fitting a Regression Line \(\hat{Y} = b_0 + b_1X\)
Given the sample data \(\{ (x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\},\)
Which sample regression line is the best?
What are the best estimators \(b_0\) and \(b_1\) for \(\beta_0\) and \(\beta_1\)?
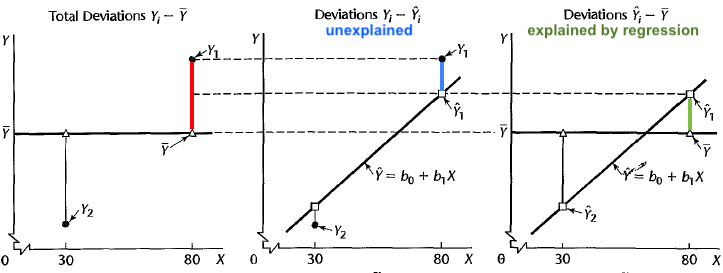
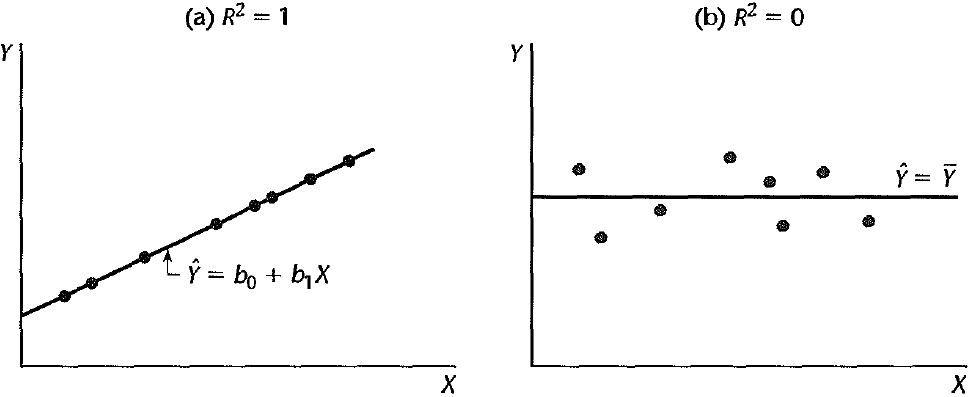
What does “best” mean? Ordinary Least Squares (OLS)
Choose \(b_0\) and \(b_1\), or sample regression line \(b_0 + b_1x\) that minimizes the sum of squared residuals \(SS_{res}\)
# A tibble: 234 × 11 manufacturer model displ year cyl trans drv cty hwy fl class <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr> 1 audi a4 1.8 1999 4 auto… f 18 29 p comp… 2 audi a4 1.8 1999 4 manu… f 21 29 p comp… 3 audi a4 2 2008 4 manu… f 20 31 p comp… 4 audi a4 2 2008 4 auto… f 21 30 p comp… 5 audi a4 2.8 1999 6 auto… f 16 26 p comp… 6 audi a4 2.8 1999 6 manu… f 18 26 p comp… 7 audi a4 3.1 2008 6 auto… f 18 27 p comp… 8 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp… 9 audi a4 quattro 1.8 1999 4 auto… 4 16 25 p comp…10 audi a4 quattro 2 2008 4 manu… 4 20 28 p comp…# ℹ 224 more rows
R Lab: Highway MPG hwy vs. Displacement displ
plot(x =mpg$displ, y =mpg$hwy, las =1, pch =19, col ="navy", cex =0.5, xlab ="Displacement (litres)", ylab ="Highway MPG", main ="Highway MPG vs. Engine Displacement (litres)")
plot(x =mpg$displ, y =mpg$hwy, las =1, pch =19, col ="navy", cex =0.5, xlab ="Displacement (litres)", ylab ="Highway MPG", main ="Highway MPG vs. Engine Displacement (litres)")abline(reg_fit, col ="#FFCC00", lwd =3)
Estimation for \(\sigma^2\)
Think of \(\sigma^2\) as variance around the line or the mean square (prediction) error.
The estimate of \(\sigma^2\) is the mean square residual\(MS_{res}\):